VMware offers many enterprise features, among them there are three important features which will make sure the vSphere infrastructure and hosted Workloads are highly available. All these features are enabled at VMware vCenter Server level and which requires specific licensing as well.
In this blog I will brief below VMware availability features. Each of these features plays a part in ensuring hosts and the VMs that reside on them function at a high-performance level, even in the event of a host failure. Although these features can be used in conjunction to safeguard your environment, each of these three features performs a unique task, and users should take care not to confuse them.
- VMware vSphere High Availability (HA)
- VMware Distributed Resource Scheduler (DRS)
- VMware vSphere Fault Tolerance (FT)
VMware vSphere High Availability (HA)
vSphere HA provides high availability for virtual machines by pooling the virtual machines and the hosts they reside on into a cluster. High Availability is feature of vCenter Server and requires Standard license. To configure HA vCenter is compulsory but after configuration HA will work even if vCenter is down.
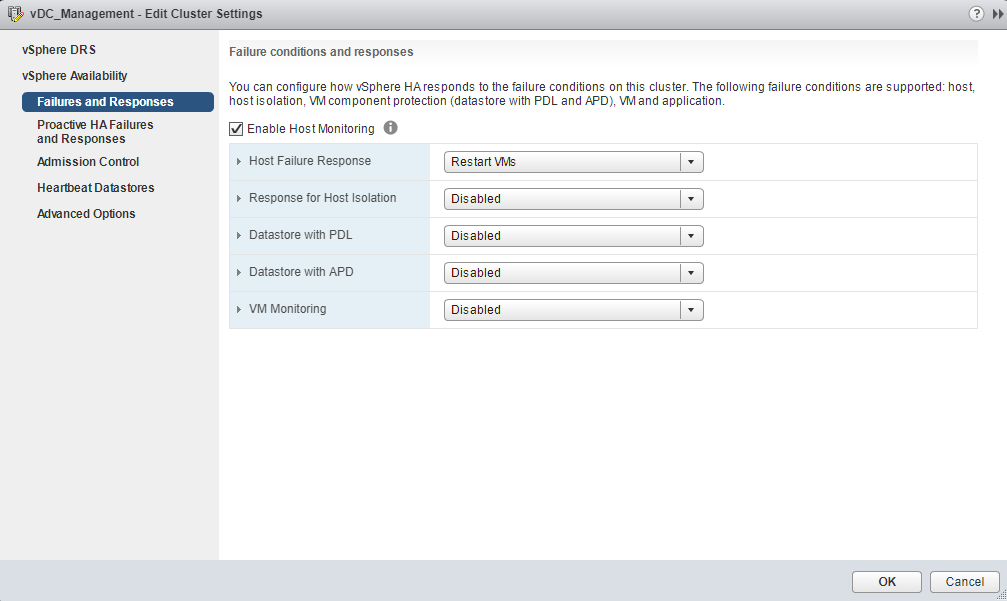
Host Monitoring – Hosts in the cluster are monitored and in the event of a failure, the virtual machines on a failed host are restarted on alternate hosts.
Guest Monitoring – vSphere HA also has a feature of VM Monitoring, if Guest OS fails this will restart the Operating system automatically. This feature used VMware Tools to check the Guest heartbeat.
Application Monitoring – the agent on an ESXi host can monitor heartbeats of applications running inside a VM. If an application fails, the VM is restarted, but it stays on the same host. This type of monitoring requires a third-party application monitoring agent and VMware Tools.
How Vsphere HA Works …
The vSphere HA introduces master and slave concept for HA agent except during network partitions. When you enable vSphere HA, an election happens, and master node and slave nodes will get elected. Any agent can serve as a master, and all others will be considered as slaves in a cluster. A master agent is responsible for monitoring the health and restarting of VMs if any of the Host/VM go down. The slave agents forward information to the master node and restart any VM as directed by master node. The HA agent, either it is a master or slave, it implements the VM/App monitoring feature which allows it to restart VM in case of OS failure or restart services in case of an application failure.
Components
There are mainly three components involved in this
- vCenter Server – Core or single pane of glass for a virtual environment and is responsible for overall management of your virtual infrastructure. vCenter Server pushes the FDM agents in parallel to the ESXi hosts of the cluster for faster deployment and multiple configurations. Also, HA leverage vCenter to retrieve information about the status of VM.
- FDM Agent – The most important component of HA is Fault Domain Manager normally known as FDM in VMware vSphere environment. FDM agent is introduced from vSphere 5.0 prior to that Automatic Availability Manager (AAM) agent exists on ESX hosts. FDM is responsible for, communicating host resource information, VM states, and HA properties with other ESXi hosts that are part of vSphere Cluster. Handling heartbeat mechanisms, VM placement on hosts, and logging etc.
- HOSTD Agent – HOSTD is an agent and is responsible for powering VMs in case of any failure such host, VM etc. FDM directly talks with HOSTD agent and vCenter Server to perform HA more efficiently.
- Heartbeat – Mechanism used by HA which check if host is alive. There are two types of Heartbeat, one is Network and other is Datastore heartbeat. In Network Heartbeat Slave send network heartbeat to master and master to slave in every second. Datastore Heartbeat is and additional level of resiliency to prevent unnecessary restart attempts. Datastore heartbeat enables a master to determine the state of a host that is not reachable via management network. By default, there are two datastores get selected. But it can be possible to add more datastores.
Requirements
To configure vSphere High Availability below are the prerequisites
- All virtual machines and their configuration files must reside on shared storage, such as a SAN/NAS.
- The ESXi hosts must be configured to have access to the same virtual machine network.
- Each host in the VMware HA cluster must have a host name assigned to it and a static IP address.
- There must be CPU compatibility between the hosts. An ideal cluster is a cluster with the same hardware and memory size.
- It is recommended that you use redundant VMkernel networking configuration
- vCenter Server and vSphere ESXi requires Standard or higher license
Supported HA Scenarios
In a vSphere HA cluster, three types of host failures can be detected:
- Failure – When a host stops functioning.
- Isolation – When a host becomes network isolated.
- Partition – When a host loses network connectivity with the master host (A “Master” host is only one within the cluster, and it’s the one who is responsible for monitoring the “slave” hosts within the cluster).
How to Configure
The vSphere HA functionality is controlled at the cluster level. Navigate to the cluster >> Configure >> vSphere Availability to configure. By default, when you create a VMware vSphere cluster, vSphere HA is turned off. Click the Edit button to turn on vSphere HA and see the options available.
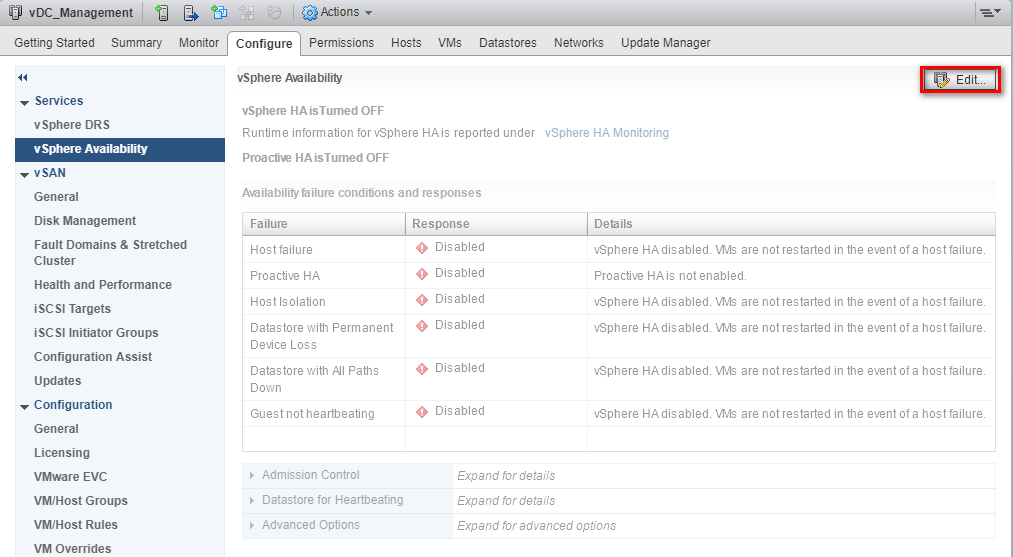
Click the checkbox next to the Turn ON vSphere HA option
Terms to Remember
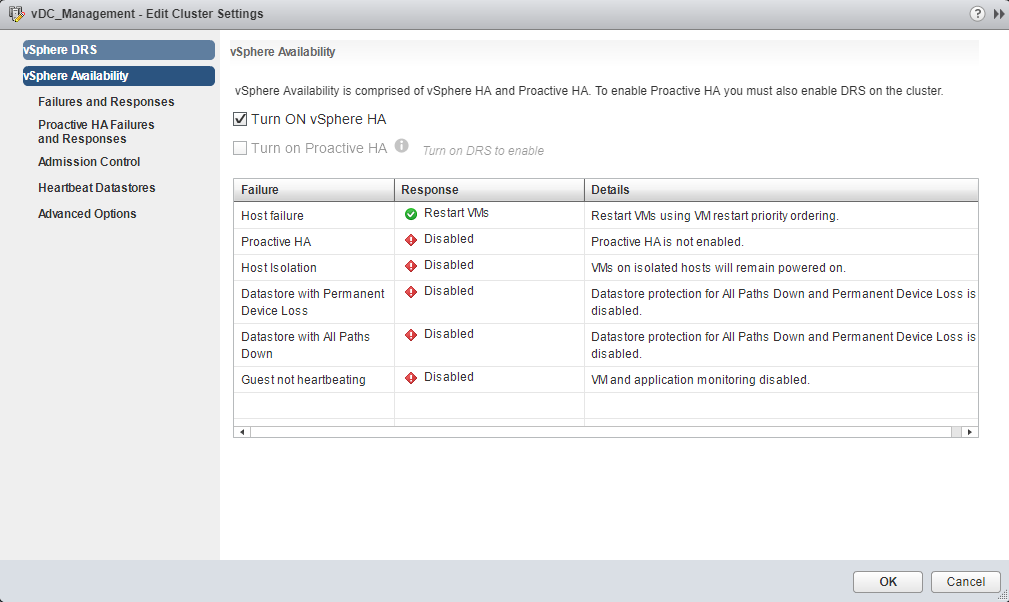
- Proactive HA – Proactive HA is a new feature integrated to monitor the physical hardware. The cluster must use vSphere DRS for correct Proactive HA. Proactive HA will detect hardware conditions of a host and allow you to evacuate the VMs before the issue causes an outage.
- Proactive HA Failures and Responses – This is how Proactive HA responds when a provider has notified its health degradation to vCenter, indicating a partial failure of that host. In the event of a partial failure vCenter Server can proactively migrate the VMs running on that host to a healthier host.
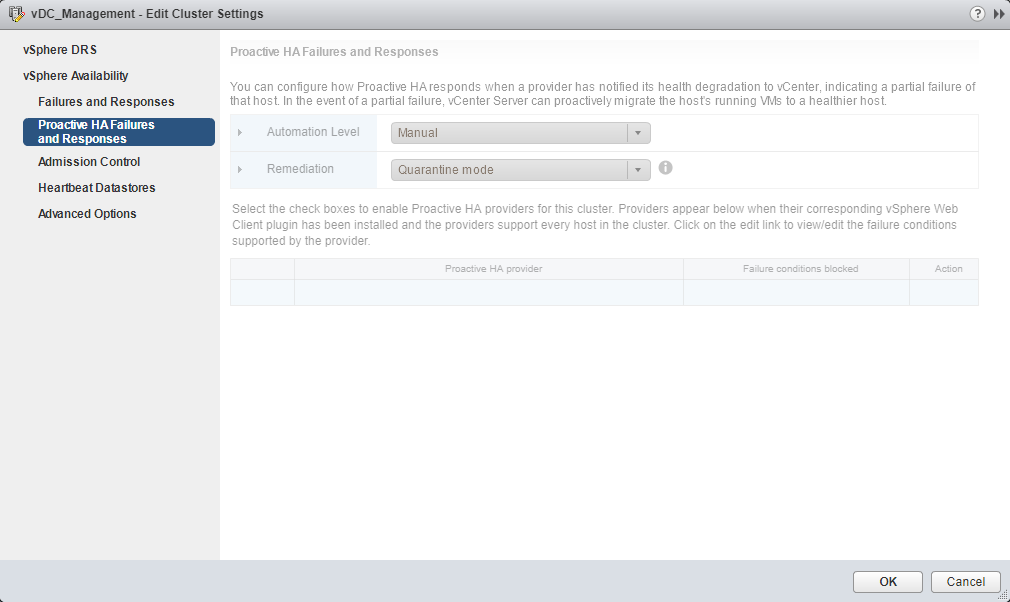
- Admission Control – Admission control is a policy used by vSphere HA to ensure failover capacity within a cluster. Increasing the value of host failures cluster tolerates will increase the availability constraints and capacity reserved.
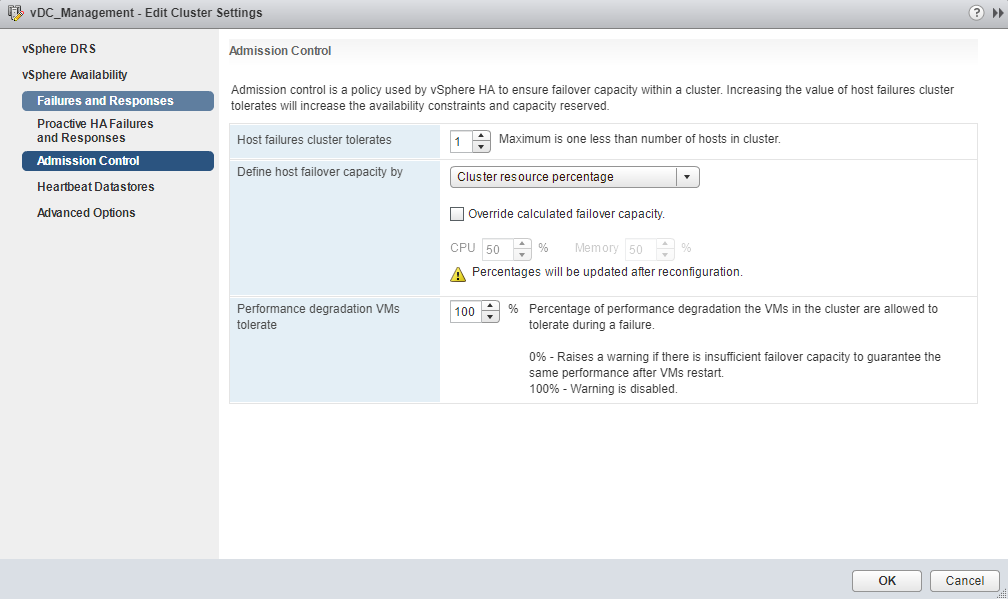
- Failures and Responses – This is how vSphere HA responds to the failure on this cluster. You can configure below features which decides how VMs react for different types of failures.
VMware Distributed Resource Scheduler (DRS)
VMware DRS (Distributed Resource Scheduler) is a utility that balances computing workloads with available resources in a virtualized environment. VMware DRS is constantly monitoring your vSphere Cluster and making sure that your VMs are getting the resources they’re asking for, the most efficiently. VMware Distributed Resource Scheduler (DRS) is checking the performance of your VMs and gives placement decisions to which host within the cluster shall VM be migrated. To configure and work DRS vCenter server is must, DRS will not work if vCenter is down.
Requirements
- VMware vCenter Server
- A VMware vSphere ESXi cluster
- vMotion network enabled on cluster hosts
- Enterprise Plus licensing
- Shared Storage between ESXi hosts
- If utilizing predictive DRS, you will need to be running vRealize Operations (vROPs) and licensing
How to Configure
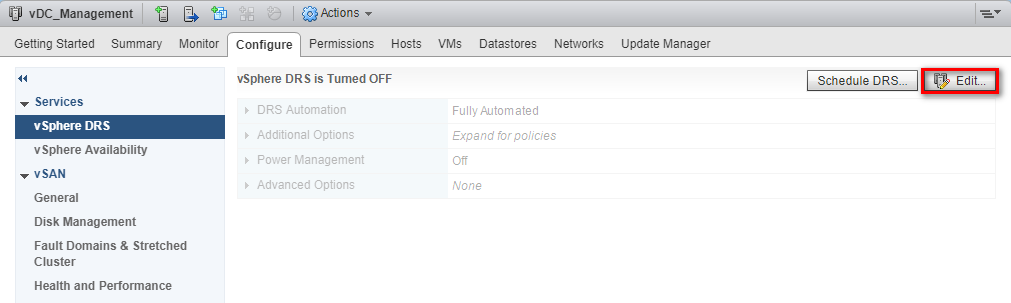
Let’s see how to enable VMware vSphere Distributed Resource Scheduler (DRS) on a cluster. DRS is configured at the cluster level and by default DRS is disabled on a cluster. Navigate to the cluster >> Configure >> vSphere DRS to configure the DRS options. Click the Edit button.
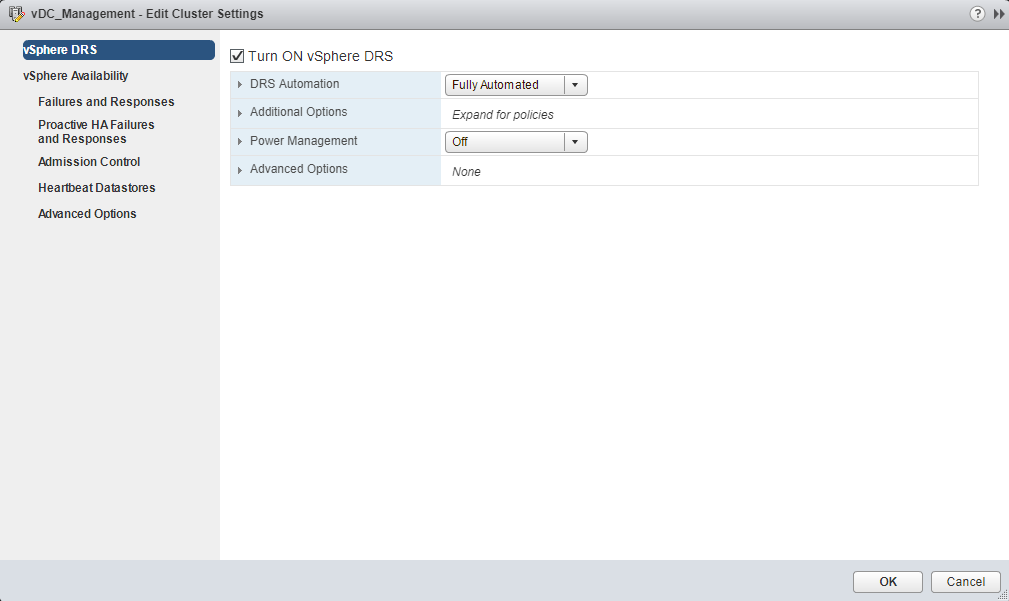
Check the box Turn ON vSphere DRS to turn on VMware vSphere DRS. Notice the options for DRS automation, Power Management, additional and advanced options. The DRS Automation level can be set to Manual, Partially Automated, or Fully Automated. This controls administrator interaction to make DRS decisions.
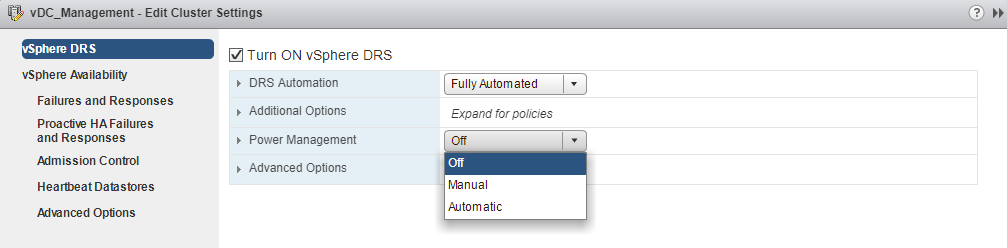
Terms to Remember
- Distributed Power Management (DPM) – VMware’s Distributed Power Manager (DPM) is part of VMware’s Distributed Resource Scheduler (DRS). DPM migrate VM guests off servers that are not in use and shut the host system down and bring up the hosts as and when required.
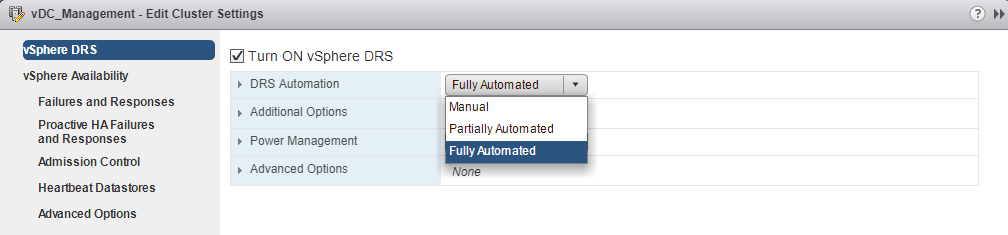
- DRS Automation – DRS automation allows administrators to decide the action when a DRS triggers like Manual (migration of VMs manually by administrators), Partially Automated(DRS suggests and administrator migrate VMs) and Fully Automated(DRS itself move VMs to other hosts)
Using vSphere HA with Distributed Resource Scheduler (DRS) combines automatic failover with load balancing. After the vSphere HA has moved virtual machines to different hosts, the combination can result in a more balanced cluster.
VMware vSphere Fault Tolerance (FT)
VMware vSphere Fault Tolerance (FT) provides continuous availability for applications (with up to four virtual CPUs) by creating a live shadow instance of a virtual machine that mirrors the primary virtual machine. If a hardware outage occurs, vSphere FT automatically triggers failover to eliminate downtime and prevent data loss. After failover, vSphere FT automatically creates a new, secondary virtual machine to deliver continuous protection for the application.
Requirements
Fault Tolerance require below prerequisites must be fulfilled
- CPUs that are used in host machines for fault tolerant VMs must be compatible with vSphere vMotion.
- Intel Sandy Bridge or later, Avoton is not supported, AMD Bulldozer or later
- At least 1Gb Network Card, 10Gb is recommended. A FT Logging Network is must
- Any Shared storage is supported like FC, NFS or iSCSI but local storage is not supported
- FT supported in vSphere Standard(2vCPUs), Enterprise(2vCPUs) and Enterprise Plus(8vCPUs) licenses.
- Hosts must be in HA enabled cluster
- Physical RDM are not supported
How to Configure
When configure FT on one Virtual Machine, it automatically creates secondary copy of the virtual machine. Secondary copy will be created on another host and shared datastore.
Create a FT Logging VM Kernel Network
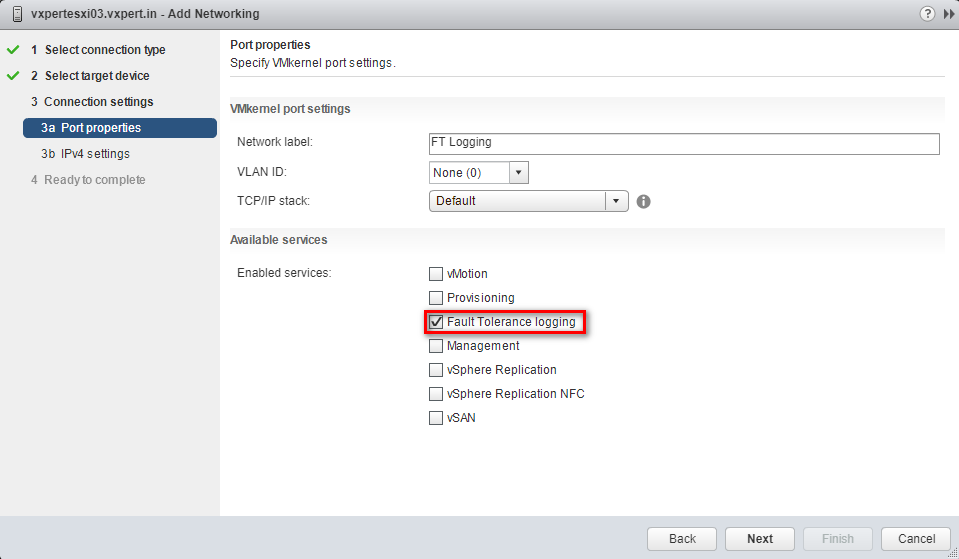
After you have your VMkernel port group created, you turn on FT by simply right clicking the virtual machine and selecting Fault Tolerance from the menu.

This will automatically create the secondary VM and initial replication will happen through vMotion Network and afterword all the sync will carried out with FT Logging Network.
Thanks,
If you have any comments, please drop me a line.
I hope this article was informative, and don’t forget to buy me a coffee if you found this worth reading.


Leave a Reply